La nasalisation dans la chanson country-western.
Un cas de phonostylistique
Catherine Lefrançois
| PDF | CITATION | AUTEUR |
Résumé
La voix country-western telle qu’elle se fait entendre sur disque dans les années 1940 et 1950 fait un usage abondant d’effets paralinguistiques dont le plus idiomatique est sans doute la nasalisation. Celle-ci présente des variations importantes d’un interprète à l’autre, dans divers enregistrements d’un même interprète mais aussi sur le plan microanalytique. Employée de manière structurée et coordonnée avec d’autres paramètres musicaux et vocaux, la nasalisation contribue fortement à l’expressivité vocale country-western et participe à la construction d’èthos aisément identifiables, prolongeant dans le chant des fonctions déjà codifiées dans la voix parlée. L’usage de la nasalisation mais surtout sa variation significative, et ce à plusieurs niveaux phonostylistiques et analytiques, participe de la diversification de la voix populaire au cours de la première moitié du XXe siècle et semble témoigner de l’apport esthétique important de la voix parlée dans la voix populaire chantée.
Mots clés : country-western ; expressivité ; nasalisation ; phonostylistique ; voix.
Abstract
Country-western voice, as heard on disc in the 1940s and 1950s, makes abundant use of paralinguistic effects, the most idiomatic being undoubtedly the nasalization. This one presents significant variations from one musician to another, in various recordings of the same performer but also on the microanalytical level. Used in a structured and coordinated way with other musical and vocal parameters, nasalization contributes strongly to the country-western vocal expressiveness and participates in the construction of easily identifiable ethos, prolonging in the singing the functions already codified in the spoken voice. The use of nasalization, but above all its significant variation at several phonostylistic and analytical levels, contributes to the diversification of the popular voice during the first half of the 20th century and seems to reflect the important aesthetic contribution of the spoken voice in popular singing.
Keywords: country-western; expressiveness; nasalization; phonostylistics; voice.
Au cours des années 1920, 1930 et 1940, de nombreux styles vocaux émergent, coexistent et se succèdent au Québec dans la chanson enregistrée : une version québécoise du crooning, la présence croissante de comédiens et d’artistes de la radio sur disque ainsi que l’arrivée de chanteurs amateurs et autodidactes dans la sphère professionnelle introduisent de nouvelles manières de dire et de chanter1Ces recherches doctorales ont été menées grâce au Conseil de recherches en sciences humaines du Canada (CRSH), plus précisément avec le soutien financier du Programme de bourses d’études supérieures du Canada.. L’effervescence que connaît l’industrie du disque dans les années 1920 est freinée par la Grande Dépression mais la fin des années 1930 voit renaître une prospérité économique qui se traduit par un retour en force du divertissement populaire, porté par la radio, les variétés et une industrie du disque qui recommence à miser sur la nouveauté.
C’est dans ce contexte qu’apparaît le country-western au Québec au cours des années 1940. La voix des chanteurs country-western de cette période se distingue par l’usage de nombreux effets paralinguistiques affectant le timbre, l’un des plus idiomatiques étant assurément la nasalisation. Souvent mentionnée comme principale caractéristique des voix country et country-western2Aux États-Unis, le mot country avait une connotation rurale forte tandis que western a d’abord été utilisé pour désigner des formes plus urbaines apparues à la fin des années 1930 comme le western swing puis le honky tonk. Au Québec, les termes ont été inversés. Dès l’apparition des premiers enregistrements country, on parle de musique western, terme alors en vogue rattaché à la fois à la production musicale états-unienne et au film western. Le mot western s’entoure cependant progressivement, au Québec, d’une connotation péjorative liée à son rejet, et dans les années 1980 le mot country a alors été utilisé dans une tentative de légitimer cette musique. Afin … Continue reading, les modalités précises de son utilisation dans ces genres n’ont cependant jamais été décrites avec précision. Son emploi dans des discours dénigrants et le recours à des termes péjoratifs pour la désigner pourraient par ailleurs nous amener à penser que sa présence est parfois nettement exagérée ; parler de la nasalité de la voix country relève presque du lieu commun. Il convient de vérifier s’il y a bien présence de nasalisation dans ce répertoire et comment, précisément, elle s’exprime et s’articule, puis ce que cela nous apprend sur le premier country-western québécois.
L’approche utilisée ici s’inscrit dans la foulée des travaux récents menés par Serge Lacasse (2010) sur la voix chantée, et en particulier sur la phonostylistique appliquée à la musique. Issue entre autres des travaux de Pierre Léon (2005), la notion de phonostyle fournit un cadre théorique qui permet, selon le niveau analytique privilégié, d’identifier des traits vocaux rattachés à l’expressivité (niveau microanalytique), au contenu narratif des œuvres prises individuellement (niveau protagonistique ou opéral), au style personnel d’un interprète (niveau individuel) ou encore à un genre musical (niveau générique). Cet article tente de cerner l’apport de la nasalisation aux divers phonostyles du premier country-western québécois.
Le corpus
Cet article découle d’une recherche plus vaste portant sur la période de structuration du country-western au Québec (Lefrançois 2011). À l’origine, la période ciblée s’étendait entre 1942, année de parution des premiers enregistrements, et 1957, année où apparaissent les premiers indices d’autonomisation du genre. Les enregistrements dont il sera ici question ont tous été produits dans les années 1940.
Si la radio a sans contredit favorisé la diffusion d’un premier country-western québécois, les performances vocales qui nous sont aujourd’hui accessibles sont issues de la production phonographique commerciale. Quelques adaptations de chansons tirées de films westerns circulaient au Québec dès les années 1930. Toutefois, ces enregistrements ont été réalisés par des artistes qui se consacraient à des styles musicaux variés, comme Ludovic Huot (1897-1968) ou Lionel Parent (1905-1980). Ce n’est qu’en 1942, avec les débuts sur disque de Roland Lebrun (1919-1980), que commence véritablement l’histoire phonographique du country-western. À la suite de celui qu’on surnommait « le soldat Lebrun », d’autres artistes présentant le même profil font leurs débuts sur disque : Paul Brunelle (1923-1994), Willie Lamothe (1920-1992) puis Marcel Martel (1925-1999), pour ne nommer que les plus connus, reprennent la formule proposée par Lebrun, soit celle de l’auteur-compositeur-interprète amateur s’accompagnant à la guitare.
Ces quatre chanteurs sont assurément les plus représentatifs du corpus et les plus marquants, tant à cause de la durée de leur carrière que par le nombre de phonogrammes produits. Ils évoluent dans les années 1940 au sein de compagnies de disques généralistes, soit chez Compo sous étiquette Starr (Lebrun et Martel) et chez RCA Victor (Lamothe et Brunelle). Le corpus se présente sous la forme d’enregistrements sur disques 78 tours et 45 tours ; les analyses ont cependant été effectuées à partir de versions déjà numérisées et commercialisées sur disques compacts de ces enregistrements originaux, qui ont fait l’objet d’un traitement visant à éliminer les bruits causés par leur détérioration. Ces procédés affectent surtout les hautes fréquences, et les zones du spectre sonore modifiées de la manière la plus radicale sont considérablement plus élevées que celles correspondant aux variations de timbre induites par la nasalisation.
Les enregistrements analysés proviennent essentiellement de compilations visant la préservation du patrimoine enregistré et qui présentent une facture soignée tant sur le plan de la reproduction sonore que des données discographiques fournies. Les enregistrements de Roland Lebrun ont été tirés de la compilation Le soldat Lebrun. Les années Starr, 1942-1953 (Disques XXI), et celles de Marcel Martel, Paul Brunelle et Willie Lamothe proviennent de la compilation Country Québec. Les pionniers et les origines, 1925-1955, éditée chez Frémeaux et associés. Les exemples visuels sont présentés essentiellement sous la forme de spectrogrammes, générés à l’aide du logiciel Sonic Visualiser, développé par le Centre for Digital Music du collège Queen Mary de l’Université de Londres et de graphiques montrant les formants, extraits à l’aide du logiciel Praat, élaboré par Paul Boersma et David Weenink de l’Université d’Amsterdam.
La production et les traits acoustiques de la nasalisation
En français parlé, la nasalisation est un mécanisme essentiel à la production des voyelles et des consonnes nasales. Dans l’analyse du corpus country-western, la nasalisation sera cependant envisagée en tant que modificateur paralinguistique, c’est-à-dire en tant que trait suprasegmental superposé à la chaîne phonologique. Ainsi, même une voyelle nasale comme le [a᷄] peut faire l’objet d’une nasalisation supplémentaire, ce qui crée un timbre nasal perceptible et davantage marqué que celui nécessaire à la production de la voyelle.
La nasalité peut constituer un trait vocal individuel distinctif et être présente de manière permanente chez un locuteur ; elle fait alors partie de ce que Poyatos appelle les qualités premières (Poyatos 1993, p. 175). En effet, la voix d’un individu présente des résonances à prédominance soit orale, soit nasale, ou plus rarement pharyngale qui dépendent des résonateurs les plus efficaces dans la transmission du signal vocal : cette situation varie en fonction de la morphologie de chacun (ibid., p. 178).
La nasalisation peut par ailleurs faire l’objet d’une production contrôlée. Elle est nécessaire à l’énonciation des voyelles nasales ([a᷄] [ɛ᷉] [œ᷉] [ɔ᷉]) et des consonnes nasales ([m] [n]), mais toutes les voyelles semblent pouvoir être nasalisées à des degrés divers, comme c’est le cas dans plusieurs accents régionaux de la langue anglaise qui ne comporte pourtant que des voyelles orales. On parlera donc de voyelles nasales dans le cas des voyelles linguistiques nécessitant la nasalisation pour leur production et de voyelles nasalisées lorsqu’une voyelle orale fera l’objet d’une nasalisation perceptible mais non nécessaire à la phonation, ou encore lorsqu’une voyelle nasale sera exagérément nasalisée. Le terme nasalisation désignera la mise en action des processus physiologiques, volontaire ou non, dont résulte la production de la nasalité.
La nasalité résulte de la présence de résonances nasales dans le transfert du signal vocal, résonances induites par l’abaissement du voile du palais, aussi appelé velum, soit la partie molle et postérieure du palais qui se termine par la luette. Au cours de la phonation, le voile du palais est naturellement relevé et bloque le passage entre le pharynx et les fosses nasales (Le Huche et Allali 2001, p. 18), constituées de deux cavités s’étendant du nez au pharynx. Pour la phonation des consonnes et des voyelles nasales, le voile du palais s’abaisse, créant ainsi l’ouverture vélaire qui permet aux fosses nasales d’agir comme résonateur. L’abaissement du voile du palais n’est pas le seul mécanisme en jeu dans la phonation des voyelles nasales : la position de la langue joue aussi un rôle dans l’identité et l’articulation de ces voyelles (Demolin et al. 2003, p. 461).
À chaque voyelle nasale correspond une voyelle orale. Tous les autres paramètres articulatoires étant semblables par ailleurs, on peut dire grossièrement que l’abaissement du voile du palais convertit la voyelle orale [ɛ] en voyelle nasale [ɛ᷉]. Par le même procédé, [œ] devient [œ᷉], [a] devient [a᷄], et [ɔ] devient [ɔ᷉]. La nasalité peut cependant être présente sans pour autant être commandée par les besoins de la phonation, et toutes les voyelles peuvent être plus ou moins nasalisées sans pour autant perdre leur identité. La voyelle orale postérieure [a] (comme dans le mot pâte), par exemple, possède son pendant nasal, la voyelle nasale postérieure [a᷄] (comme dans le mot quand). Pour passer du son [a] au son [a᷄], Demolin et al. (2003, p. 456-457) ont observé chez plusieurs sujets un abaissement du velum si important que la luette entrait en contact avec la racine de la langue. On peut s’imaginer qu’entre un tel abaissement et une position parfaitement relevée du voile du palais, une articulation intermédiaire serait possible et permettrait de nasaliser la voyelle [a], sans pour autant lui faire perdre son identité et la transformer en [a᷄]. Dans les exemples tirés du corpus, on verra que la voyelle orale [ɛ] peut se présenter sous une forme nasalisée sans pour autant être perçue comme la nasale [ɛ᷉].
Plusieurs études tendent à montrer que la nasalisation n’affecte pas toutes les voyelles orales de la même manière. Birch et al. (2002, p. 68-69) ont effectué des tests de perception du degré de nasalité de la voyelle [a] à partir de segments chantés par des chanteurs d’opéra professionnels et pour lesquels avaient été mesurés le débit d’air nasal et l’ouverture vélaire. Ils ont notamment conclu que pour cette voyelle, il était difficile d’établir une corrélation exacte entre le degré d’ouverture et la nasalité perçue ; certains chanteurs produisaient cette voyelle avec le voile du palais passablement abaissé sans pour autant produire une nasalité perceptible. D’autres chanteurs avaient au contraire un timbre perçu comme nasal qui s’accompagnait d’une ouverture vélaire minime.
Cette étude a aussi montré que si les chanteurs d’opéra utilisent très souvent l’abaissement du voile du palais sur la voyelle [a], ils le font plus rarement pour les voyelles [i] et [u]. L’étude de Sundberg et al. (2007, p. 134) suggère que l’ouverture vélaire, pour la voyelle [a], offrirait l’avantage d’atténuer le premier formant de cette voyelle sans affecter le niveau sonore des formants 3, 4 et 5, ce qui aurait ainsi pour effet d’augmenter l’intensité relative de ces formants, qui s’étaient de plus agrégés. Les auteurs en concluent que, pour la voyelle [a], une ouverture vélaire contribue à la création du formant du chanteur et participe ainsi à une bonne projection de la voix. Pour les voyelles [i] et [u] cependant, l’ouverture vélaire combinée à la résonance des fosses nasales étend le premier formant sur une bande de fréquence plus large, ce qui contribue à donner un timbre nasal bien perceptible à la voyelle ainsi produite : les chanteurs d’opéra professionnels ont donc tendance à éviter cette technique pour les voyelles [i] et [u].
Sur le plan acoustique, la nasalisation est un phénomène complexe auquel, selon Raymond Kent (1993, p. 104), trois principaux effets peuvent être rattachés. Premièrement, l’abaissement du voile du palais introduisant une bifurcation dans le conduit vocal, il crée des antiformants, c’est-à-dire des régions du spectre harmonique qui sont considérablement moins intenses. Ceux-ci seraient situés entre 500 Hz et 1 800 Hz selon John Laver (1980, p. 91), et entre 800 Hz et 2 000 Hz selon le Laboratoire de phonétique et phonologie de l’Université Laval, des valeurs proches du deuxième formant pour la voix parlée3Toutes les valeurs typiques des formants qui seront données ultérieurement pour les voyelles françaises sont tirées du répertoire Identification des sons du français mis en ligne par le Laboratoire de phonétique et phonologie de l’Université Laval au http://www.phonetique.ulaval.ca.. Deuxièmement, l’ouverture vélaire cause un allongement du canal par lequel circule le signal vocal, ce qui amplifie les fréquences de résonance les plus basses. Chez les hommes, un formant nasal est ainsi créé autour de 300 Hz. Troisièmement, les cavités nasales absorbent une part de l’énergie acoustique, causant à la fois une réduction de l’énergie globale de la voix et un élargissement de la bande de fréquence des formants. Laver (ibid., p. 91) observe d’ailleurs une intensité forte des formants autour de 2 500 Hz sur une large bande d’environ 1 000 Hz.
Ces propriétés acoustiques de la nasalisation s’accordent bien avec les observations de Birch et al. et de Sundberg et al. En effet, si la nasalisation augmente l’intensité des formants situés autour de 300 Hz, le timbre de la voyelle [a] sera peu affecté par la nasalisation, puisque son premier formant, pour les voix masculines, se situe beaucoup plus haut que 300 Hz, soit autour de 760 Hz pour le français. En revanche, les voyelles [i] et [u] ont un premier formant (F1) dont la valeur typique est de 250 Hz et de 290 Hz respectivement, des valeurs situées beaucoup plus près de 300 Hz ; F1 sera conséquemment beaucoup plus affecté par les résonances nasales, ce qui modifiera considérablement le timbre de la voyelle nasalisée et contribuera à la formation d’un formant nasal renforcé.
La complexité acoustique de la nasalité pose un problème méthodologique pour l’analyse du corpus. Il est en effet très difficile de l’identifier par la simple observation du spectrogramme réalisé à partir d’un enregistrement. De plus, les analyses effectuées à partir du corpus suggèrent, comme on le verra, que la présence de nasalité s’exprimerait de manière légèrement différente d’un chanteur à l’autre sur le plan acoustique : ceci constitue un second défi dans l’identification de cette variation de timbre. Un troisième obstacle méthodologique à l’identification visuelle rapide des passages nasalisés de manière significative est la présence presque constante de cette qualité dans la voix chantée de plusieurs interprètes.
À l’instar de plusieurs autres effets paralinguistiques, la nasalisation ne peut être envisagée en termes binaires et discontinus (présence vs absence) mais se déploie sur un continuum : la voix peut être non nasalisée, peu nasalisée ou très nasalisée, et ce, avec une variété infinie de nuances. De plus, un degré de nasalité élevé peut relever d’un phonostyle individuel sans toutefois être prédéterminé exclusivement par la morphologie du chanteur. On le verra entre autres avec Roland Lebrun, dont le degré de nasalité moyen peut présenter de grands écarts. J’introduirai ici la notion de voix première, qui correspondra à la voix modale chantée d’un interprète, celle-ci pouvant varier d’un enregistrement à l’autre ou encore d’une période créatrice à l’autre, et qui pourra servir d’étalon aural permettant de mesurer les micro-variations relatives à un paramètre continu.
Les analyses sont donc fondées d’abord sur une écoute attentive visant à déterminer le degré de nasalité de chaque voyelle dans son contexte immédiat. Ainsi, en fonction du degré de nasalité dans ce qu’on considérera comme la voix première d’un chanteur, et en fonction du degré de nasalité moyen auquel il aura recours dans une chanson en particulier, les voyelles notées comme significativement nasalisées seront celles qui se démarqueront des voyelles environnantes et des autres occurrences de la même voyelle dans le même phonogramme. L’analyse spectrale ou l’extraction des formants confirmera en général clairement la perception auditive.
Analyses
Les variations interindividuelles
Une première écoute du corpus révèle que la nasalisation semble y être fortement présente, et que les chanteurs country-western ont recours à des voix premières où le degré de nasalité moyen est extrêmement variable. La perception du degré de nasalité diffère évidemment selon l’auditeur et le contexte de l’écoute : un auditeur peu familier avec la voix de Roland Lebrun pourra la trouver très nasale, alors qu’elle l’est beaucoup moins, par exemple, que celle de Marcel Martel. Pour la période ciblée, Paul Brunelle et Marcel Martel ont les voix premières qui semblent les plus nasales. Chez Roland Lebrun et Willie Lamothe, la nasalisation est employée occasionnellement et elle est moins facilement perceptible en dehors de ces effets passagers. Les analyses acoustiques tendent à confirmer cette perception et les exemples à venir montreront les traces d’un degré de nasalité moyen pour chacun de ces interprètes. Les exemples ont tous été effectués à partir d’occurrences chantées sur la voyelle pour laquelle, on l’a vu plus haut, le seuil de perception de la nasalité est assez bas et les empreintes acoustiques, bien visibles.
En français parlé, la voyelle présente des formants dont les valeurs, pour les locuteurs masculins, s’approchent typiquement de 250 Hz, 2 250 Hz, 2 980 Hz et 3 280 Hz, pour F1, F2, F3 et F4 respectivement. Chez un chanteur qui présente une voix première très peu nasalisée comme Roland Lebrun, les trois premiers formants, soit ceux qui déterminent le plus fortement l’identité de la voyelle, sont bien définis4Les exemples désignés par des lettres et précédés du même chiffre sont tirés du même extrait sonore..
![Exemple 1a : Roland Lebrun, « La mort d’un cow-boy des prairies », 3e strophe, [i] de « amis ».](https://revuemusicaleoicrm.org/wp-content/uploads/2016/11/Lefrancois_1a.png)
Exemple 1a : Roland Lebrun, « La mort d’un cow-boy des prairies », 3e strophe, [i] de « amis »5Formants 01:42.632-01:43.706..
On peut également noter l’absence d’antiformants dans le spectre harmonique de la voyelle. De plus, bien que certains harmoniques soient moins intenses, ils sont tous visibles sur le spectrogramme de l’exemple 1b.
![Exemple 1b : Roland Lebrun, « La mort d’un cow-boy des prairies », 3e strophe, [i] de « amis ».](https://revuemusicaleoicrm.org/wp-content/uploads/2016/11/Lefrancois_1b.png)
Exemple 1b : Roland Lebrun, « La mort d’un cow-boy des prairies », 3e strophe, [i] de « amis »6Spectre harmonique 01:42.632-01:43.706..
Lorsque Roland Lebrun a recours à la nasalisation, des antiformants beaucoup plus accusés apparaissent. L’exemple 2 montre la voyelle nasalisée, avec une large bande d’antiformants située entre 600 Hz et 1 800 Hz.
![Exemple 2 : Roland Lebrun, « La vie d’un cow-boy », 1er couplet, [i] de « partis ».](https://revuemusicaleoicrm.org/wp-content/uploads/2016/11/Lefrancois_2.png)
Exemple 2 : Roland Lebrun, « La vie d’un cow-boy », 1er couplet, [i] de « partis »7Spectre harmonique 00:07.555-00:08.605.
Lebrun est, mis à part une exception dont il sera question plus loin, le chanteur du corpus qui utilise la voix première comportant le moins de nasalité. Celle de Willie Lamothe présente un peu plus de nasalité que celle de Lebrun. Sa voix présente des antiformants autour de 950 Hz ainsi qu’une bande de forte intensité autour de 2 460 Hz, ce qui semble chez lui correspondre à un élargissement du troisième formant qui a tendance à s’agréger avec le quatrième formant.
![Exemple 3a : Willie Lamothe, « Giddy-Up Sam », 1er couplet, [i] de « prairies ».](https://revuemusicaleoicrm.org/wp-content/uploads/2016/11/Lefrancois_3a.png)
Exemple 3a : Willie Lamothe, « Giddy-Up Sam », 1er couplet, [i] de « prairies »8Spectre harmonique 00:09.880-00:10.588..
![Exemple 3b : Willie Lamothe, « Giddy-Up Sam », 1er couplet, [i] de « prairies ».](https://revuemusicaleoicrm.org/wp-content/uploads/2016/11/Lefrancois_3b.png)
Exemple 3b : Willie Lamothe, « Giddy-Up Sam », 1er couplet, [i] de « prairies »9Formants 00:09.880-00:10.588..
Paul Brunelle et Marcel Martel ont assurément les voix chantées les plus nasales. La voix première de Paul Brunelle possède un degré de nasalité variable d’un enregistrement à l’autre ; elle est la plupart du temps plus nasale que celle de Willie Lamothe. Un trait acoustique marquant chez Paul Brunelle est la dispersion du deuxième formant.
![Exemple 4 : Paul Brunelle, « Mon enfant je te pardonne », [i] de « vite », 1er refrain.](https://revuemusicaleoicrm.org/wp-content/uploads/2016/11/Lefrancois_4.png)
Exemple 4 : Paul Brunelle, « Mon enfant je te pardonne », [i] de « vite », 1er refrain10Formants 00:13.490-00:14.001..
Ce trait est-il relié à la nasalité ou est-ce une caractéristique individuelle de sa voix ? Chez Marcel Martel, qui présente quant à lui une voix première toujours très nasale, les traits habituellement associés à la nasalité sont clairement présents de même qu’une bande d’antiformants assez large, presque constamment visible dans le spectre harmonique de sa voix.
![Exemple 5a : Marcel Martel, « La chaîne de nos cœurs », 2e couplet, [i] de « chérie ».](https://revuemusicaleoicrm.org/wp-content/uploads/2016/11/Lefrancois_5a.png)
Exemple 5a : Marcel Martel, « La chaîne de nos cœurs », 2e couplet, [i] de « chérie »11Spectre harmonique 01:51.502-01:52.965..
On y retrouve également une légère dispersion du deuxième formant, comme le montre l’exemple 5b, créé à partir du même extrait sonore que l’exemple 5a.
![Exemple 5b : Marcel Martel, « La chaîne de nos cœurs », 2e couplet, [i] de « chérie ».](https://revuemusicaleoicrm.org/wp-content/uploads/2016/11/Lefrancois_5b.png)
Exemple 5b : Marcel Martel, « La chaîne de nos cœurs », 2e couplet, [i] de « chérie »12Formants 01:51.502-01:52.965..
Ce trait se confirme à l’analyse d’une autre occurrence de moyennement nasalisé, un possédant un spectre harmonique et une prononciation semblable à celui des exemples 5a et 5b.
![Exemple 6 : Marcel Martel, « La chaîne de nos cœurs », 3e refrain, [i] de « brises ».](https://revuemusicaleoicrm.org/wp-content/uploads/2016/11/Lefrancois_6.png)
Exemple 6 : Marcel Martel, « La chaîne de nos cœurs », 3e refrain, [i] de « brises »13Formants 02:03.402-02:04.279..
Afin de vérifier que ce trait acoustique est bien rattaché à la nasalisation et non pas à la voyelle qui serait articulée d’une manière particulière chez Marcel Martel et Paul Brunelle, j’ai choisi une autre voyelle : [ø]. Elle subit ici une nasalisation progressive, passant d’un degré de nasalité moyen pour Marcel Martel à une nasalité de plus en plus marquée. À mesure que la voyelle se nasalise, le deuxième formant se disperse de plus en plus.
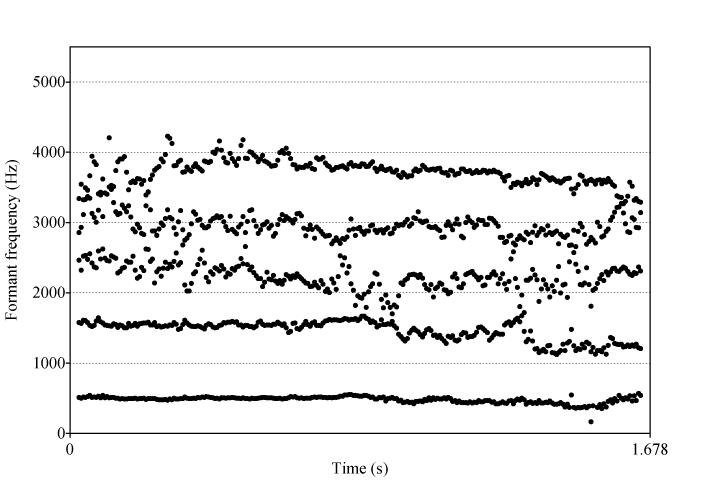
Exemple 7 : Marcel Martel, « La chaîne de nos cœurs », 1er refrain, dernière voyelle de « malheureux »14Formants 00:14.733-00:16.341..
Ces résultats me conduisent à avancer le fait que la dispersion de F2 est bel et bien un trait acoustique pouvant être associé à la nasalisation chez certains chanteurs15Il est évidemment impossible d’affirmer que ce phénomène est causé par la nasalisation. Il n’en accompagne pas moins la nasalisation chez ces deux chanteurs et ce, sur plusieurs voyelles, comme le montreront d’autres exemples à venir.. Chez Marcel Martel, on note aussi la présence d’autres traits plus couramment associés à la nasalisation, tels la création d’antiformants et l’agrégation de F3, F4 et F5. Comme le montrait aussi l’exemple 5b, la nasalisation chez Martel s’exprime également par une intensité plus forte des harmoniques autour de 2 300 Hz à 2 400 Hz.
Les variations intra-individuelles
On retrouve donc dans le corpus des variations interindividuelles importantes, tant sur le plan du degré de nasalité moyen dans la voix première de chaque interprète que sur celui de l’expression acoustique de la nasalité d’un chanteur à l’autre. On peut aussi y observer une variation du degré moyen de nasalité dans la voix première de certains chanteurs. Chez Willie Lamothe, par exemple, les chansons joyeuses et au tempo rapide sont prédominantes. Son degré moyen de nasalité a été établi à partir de ce type de chansons. Lamothe enregistre aussi, au cours des années 1940 et 1950, quelques ballades sentimentales dans lesquelles sa voix première est beaucoup plus nasalisée. Les exemples 8a et 8b permettent de comparer ces deux types de voix première chez Lamothe. Ils révèlent deux phénomènes qui confirment ici notre perception.

Exemple 8a : Willie Lamothe, « Giddy-Up Sam »16Spectrogramme 00:00.000-01:30.006..
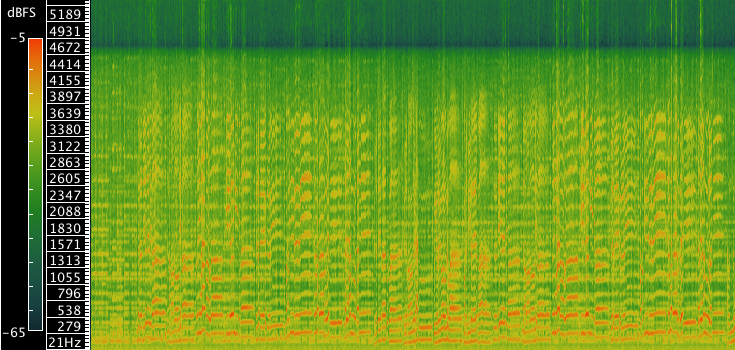
Exemple 8b : Willie Lamothe, « Ne me délaissez pas »17Spectrogramme 00:00.000-01:30.006..
Ces exemples montrent deux spectrogrammes réalisés à partir d’extraits longs (1 min 30 s) de « Giddy-Up Sam », chanson qui a été utilisée pour produire les exemples 3a et 3b, typique des chansons joyeuses de Lamothe, et de « Ne me délaissez pas », une chanson de supplication où la voix de Lamothe est plus nasalisée. Dans « Giddy-Up Sam », le fondamental, qui oscille entre 200 Hz et 430 Hz environ18Les valeurs les plus élevées correspondent aux notes chantées en second mode de phonation., est moins intense que le premier harmonique. Dans « Ne me délaissez pas », le fondamental est aussi intense que le premier harmonique, ce qui pourrait indiquer la présence d’un formant nasal. On peut aussi voir sur l’exemple 8b plusieurs zones d’antiformants.
On pourrait être tenté d’attribuer ces différences de timbre à une évolution dans la voix du chanteur. On retrouve cependant chez Lamothe cette même différence dans le degré moyen de nasalité sur des enregistrements parus simultanément. En 1948, les chansons « L’amour d’une cowgirl » et « Quand je reverrai ma province » se retrouvent en effet sur le même disque. Cette dernière chanson exprime une grande exubérance, notamment grâce à un tempo rapide et à la présence du yodel. « L’amour d’une cowgirl » raconte la solitude d’une femme abandonnée par son amant et cette valse au tempo lent, chantée en partie en mode mineur, est interprétée avec une voix beaucoup plus nasalisée. Des variations semblables se retrouvent aussi chez Paul Brunelle. Dans « Mon enfant je te pardonne », par exemple, qui raconte l’abandon d’une mère par sa fille, la voix première de Paul Brunelle semble plus nasale que pour une chanson comme dans « Sur ce vieux rocher blanc », relatant des souvenirs amoureux idylliques. Ces variations intra-individuelles, où la voix d’un même interprète est davantage nasalisée dans l’interprétation de chansons tristes, constituent un premier indice d’une possible fonction expressive de la nasalisation dans la voix country-western.
Peu de données empiriques sont disponibles sur la signification paralinguistique et expressive de la nasalisation. Une des connotations de cette variation de timbre le plus souvent évoquée est l’expression de la plainte, notamment chez Laver (1980, p. 92) et chez Poyatos (1993, p. 223), ce dernier avançant aussi que la nasalisation serait présente dans les pleurs (ibid., p. 289). Selon Aaron Fox, c’est justement afin d’évoquer la tristesse et la plainte que la nasalisation est employée par les chanteurs country états-uniens. Coordonnés avec les paroles chantées, la nasalisation et de nombreux autres effets vocaux peuvent souvent être interprétés comme des cry breaks, soit des icônes du pleur :
Les pleurs peuvent être représentés de manière iconique grâce à des effets appelés cry breaks – de courtes déformations de la ligne mélodique introduites par le falsetto, la nasalisation, des impulsions produites par la glotte ou le diaphragme affectant le flux vocal et donc la mélodie, ou par l’ajout de « bruits » articulatoires à un timbre généralement égal19« Crying […] can be iconically represented with specific inflections known categorically as “cry breaks”—sharp deformations of the melodic line effected through intermittent falsetto or nasalization, glottal or diaphragmatic pulsing of the airstream and thus the melodic line, or the addition of articulatory “noise” to an otherwise timbrally “smooth” vocal tone » (Fox 2004, p. 276)..
Pour Fox, ces effets incarnent des affects précis, et leur usage découle à la fois des traditions stylistiques et des visées expressives de l’interprète :
Ces pleurs stylisés […] sont à la fois des marqueurs répandus de certains sous-genres (le style « hillbilly », par exemple autorise la production d’autant de « cry breaks » qu’il est physiologiquement possible) mais est également coordonné de manière spécifique avec les chansons tristes, les verbes décrivant l’action de pleurer ainsi que les passages émotionnellement chargés20« “Crying” effects […] are both generalized aspects of a subgeneric style (“hillbilly” style for example, permits as many cry breaks as possible subject to phonological constraints) and specifically coordinated with “sad” songs, verbs of crying, and affectively potent moments » (Fox 2004, p. 280)..
Les quelques exemples mentionnés plus haut pourraient en effet suggérer que la nasalisation correspondrait, dans le corpus, à l’expression de sentiments négatifs. En plus de constituer un trait phonostylistique générique, présent chez tous les chanteurs majeurs du corpus, et individuel, employé à des degrés divers chez ces interprètes, la nasalisation semble donc être variée en fonction du type de récit que présentent les chansons, rendant du coup la nasalisation significative à un autre niveau analytique, celui de chaque chanson prise individuellement et des protagonistes qu’elle met en scène.
Sans en décrire les modalités précises, Fox (2004, p. 280) avance que la variation des effets paralinguistiques visant à exprimer la tristesse et la plainte seraient coordonnés avec les mots du texte chanté. On a par ailleurs l’intuition, à l’écoute des chansons, que l’effet de plainte s’accomplit également à travers la variation d’autres paramètres, puisque la nasalisation est également présente dans des chansons n’exprimant pas forcément la tristesse. Comment, précisément, la nasalisation opère-t-elle dans la construction de ces représentations de la tristesse, du pleur et de la plainte ? L’analyse des microvariations de ce modificateur paralinguistique s’impose.
Avant de poursuivre, et puisque l’analyse des microvariations de timbre m’amèneront à parler d’expressivité, il faut préciser dans quelle perspective j’utilise ce concept. À propos des effets paralinguistiques, Poyatos (1993) avance qu’ils sont l’indice d’émotions, d’attitudes, de sentiments. Il s’agit d’un vocabulaire qui va de soi lorsqu’on étudie la production vocale spontanée. La performance vocale chantée relève cependant d’un contexte esthétique et, dans le cadre d’une analyse musicale, il est impossible, voire peu pertinent, de savoir si un interprète ressent ou pas telle émotion ou encore si, par sa performance, il produit cette émotion chez un auditeur. Dans la signification accordée aux effets paralinguistiques et à la variation de tous les autres paramètres vocaux, il m’apparaît moins subjectif et plus fonctionnel d’envisager ces variations non pas comme relevant d’une émotion mais comme concourant à l’élaboration d’un ou de plusieurs éthos, situant du coup l’analyse sur le plan de la médiation entre l’émetteur et le récepteur.
La notion d’èthos présente deux définitions qui permettent de l’utiliser dans ce contexte, sans dénaturer le sens usuel du terme. D’une part, en rhétorique classique, l’èthos est rattaché à la représentation du caractère du locuteur, se rapprochant en cela des fonctions attribuées aux effets paralinguistiques pour la parole. D’autre part, dans la conception proposée par Maingueneau (Maingueneau 1984, p. 100 ; cité dans Woerther 2007, p. 13) pour l’analyse du discours, l’èthos se traduit dans un « ton » particulier. Si Maingueneau donne surtout des précisions quant aux èthos incarnés dans des représentations du corps et dans la manière de se « mouvoir dans l’espace social », des « modes de présence au monde » (Maingueneau 1993, p. 139-140 ; cité dans ibid., p. 12-13), on pourrait envisager des èthos construits grâce aux « tons » de la voix et à d’autres éléments que compose la rhétorique d’une chanson ou d’une performance vocale. L’èthos selon Maingueneau relève de la posture, ce qui situe ce concept à la croisée de la production et de la réception, sans privilégier l’une au détriment de l’autre. De plus, Frédérique Woerther (ibid., p. 8) souligne que l’èthos est lié à la notion de style ; son usage dans une analyse phonostylistique pourrait donc être pertinent. La nasalisation et les autres microvariations analysées ici sont donc envisagées non pas comme relevant de l’expression d’émotions mais comme participant à la construction d’èthos variés. La tristesse, la solitude, ou, ailleurs, l’exubérance, ne constituent donc pas de ce point de vue des sentiments mais des représentations codifiées de ceux-ci.
Les microvariations
Les variations du degré de nasalité dans un enregistrement mettent en jeu plusieurs autres phénomènes liés, notamment, à la hauteur et à l’intensité. Afin de bien comprendre comment ces divers paramètres opèrent et selon quel contexte, il serait utile d’analyser en profondeur une performance vocale dans son entier. La chanson de Marcel Martel « La chaîne de nos cœurs » présente de nombreuses microvariations de la nasalisation dans un contexte où celles-ci semblent de prime abord contribuer à la représentation de la plainte et de la tristesse. Enregistrée en 1947, « La chaîne de nos cœurs » est une adaptation de la chanson de Hank Snow « You Broke the Chain That Held Our Hearts », parue en 1945. La version de Martel semble beaucoup plus plaintive et plus proche de la lamentation que celle de Snow, dont la voix est à la fois plus légère et moins nasalisée. Dans les deux chansons, le narrateur s’adresse à une femme qui l’a quitté. Tandis que la chanson de Hank Snow met l’accent sur le retour possible de la femme et sur son amour qui demeure malgré leur séparation, la version de Marcel Martel a évacué toute référence à une éventuelle fin heureuse et ne parle que de la souffrance du narrateur.
La modification du style vocal dans l’adaptation française semble s’accorder avec le glissement de sens qu’ont subi les paroles. Dans cet enregistrement, plusieurs voyelles sont significativement plus nasalisées, cette variation pouvant être mise en évidence en juxtaposant deux occurrences de la même voyelle.
Exemples 9a et 9b : Marcel Martel, « La chaîne de nos cœurs ».
L’exemple 9a fait d’abord entendre un typique de la voix première de Marcel Martel21Il s’agit du [i] correspondant à l’exemple 5 présenté plus haut. puis dans l’exemple 9b, un [i] tiré du même enregistrement est beaucoup plus nasalisé. L’extraction des formants confirme la perception auditive : le deuxième formant de ce second [i] est manifestement plus dispersé que celui du premier22On se rappellera que la dispersion de F2 est l’une des marques de la nasalisation chez Marcel Martel..
![Exemple 10a : Marcel Martel, « La chaîne de nos cœurs », 2e couplet, [i] de « chérie ».](https://revuemusicaleoicrm.org/wp-content/uploads/2016/11/Lefrancois_10a.png)
Exemple 10a : Marcel Martel, « La chaîne de nos cœurs », 2e couplet, [i] de « chérie »23Formants 01:51.502-01:52.965..
![Exemple 10b : Marcel Martel, « La chaîne de nos cœurs », 1er couplet, [i] de « quittes ».](https://revuemusicaleoicrm.org/wp-content/uploads/2016/11/Lefrancois_10b.png)
Exemple 10b : Marcel Martel, « La chaîne de nos cœurs », 1er couplet, [i] de « quittes »24Formants 01:00.929-01:01.637..
Une écoute attentive révèle que dans « La chaîne de nos cœurs », ces voyelles davantage nasalisées s’accompagnent de deux phénomènes : la présence fréquente d’une nasalisation non pas soudaine mais progressive et l’existence de deux types de voyelles nasalisées qui présentent un contraste significatif sur le plan dynamique.
Dans « La chaîne de nos cœurs », plusieurs voyelles subissent une nasalisation progressive. C’est notamment le cas du [œ] de « cœur » et du [ø] de « malheureux » dans plusieurs de leurs occurrences, pour lesquels le deuxième formant se disperse de plus en plus et F3, F4 et F5 convergent graduellement.
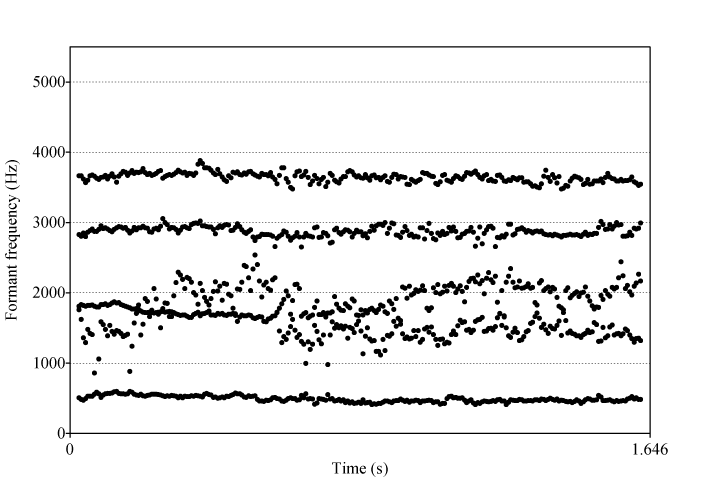
Exemple 11 : Marcel Martel, « La chaîne de nos cœurs », 1er refrain, voyelle centrale de « cœur »25Formants 00:09.766-00:11.412..
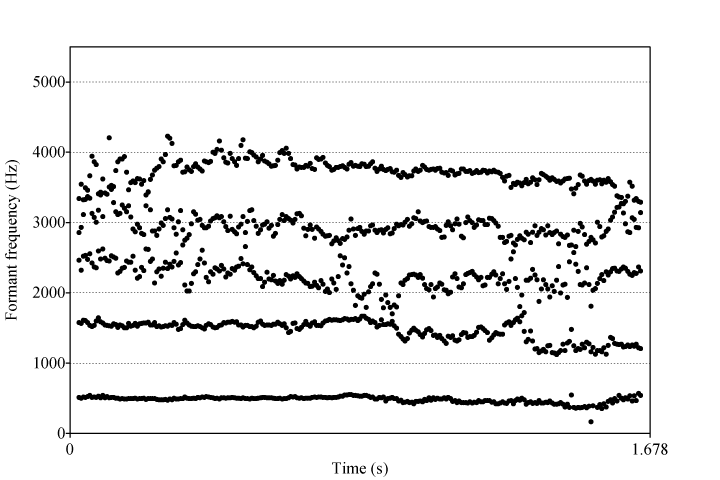
Exemple 12 : Marcel Martel, « La chaîne de nos cœurs », 1er refrain, voyelle finale de « malheureux »26Formants 00:14.733-00:16.341..
Les exemples 13 et 14 font entendre ces voyelles.
Exemple 13 : Marcel Martel, « La chaîne de nos cœurs », 1er refrain, voyelle centrale de « cœur ».
Exemple 14 : Marcel Martel, « La chaîne de nos cœurs », 1er refrain, voyelle finale de « malheureux ».
Chacune a été montée en boucle afin de permettre l’audition de la nasalisation progressive, qui n’est pas facilement détectable sans une écoute répétée, étant donné la brièveté des voyelles chantées.
On retrouve sept de ces voyelles progressivement nasalisées dans « La chaîne de nos cœurs » et elles correspondent toutes à des voyelles terminales, chantées à la toute fin d’une phrase. D’ailleurs, sur les 27 voyelles significativement nasalisées qui ont été identifiées dans la performance, 15 sont situées en fin de phrase. La chanson comporte 20 phrases, chacune correspondant à un vers, ce que nous indiquent à la fois le schéma rythmique et la disposition des respirations. Dans l’interprétation de Marcel Martel, 15 phrases sur 20 comportent une voyelle terminale significativement nasalisée, ce qui en fait un procédé saillant. Et lorsqu’une seule voyelle est nasalisée dans une phrase, elle est systématiquement située à la fin. En plus de la nasalisation progressive de plusieurs voyelles chantées, il semble donc y avoir également une intensification de la nasalisation à l’échelle de la phrase.
Le même effet touche la structure formelle de la chanson, en particulier dans les refrains, où le degré de nasalité moyen augmente de manière continue, une caractéristique facilement perceptible à l’écoute de la première puis de la dernière phrase de chaque refrain. L’écoute du premier puis du dernier refrain de la chanson donne la même impression alors que la voix de Marcel Martel semble être de plus en plus nasalisée à mesure que se déroule la performance. L’intensification de la nasalisation touche donc trois échelons structurels, soit celui des voyelles, celui de la phrase et celui des sections formelles.
Le second phénomène observé concerne les profils dynamiques contrastants appliqués aux voyelles les plus nasalisées, qui correspondent toutes à des accents toniques et sont toutes soutenues par des valeurs longues. Les voyelles progressivement nasalisées et celles situées en fin de phrase s’accompagnent en général d’une baisse d’intensité marquée. Ces baisses d’intensité sont naturelles puisqu’elles correspondent à la fin d’une phrase ainsi que, le plus souvent, à la fin de la phase d’expiration. De manière intéressante, il semble exister ici une corrélation entre nasalisation en fin de souffle et stabilité de la hauteur : les voyelles terminales significativement nasalisées sont beaucoup plus stables que celles qui ne le sont pas. En général, lorsque l’intensité d’exécution doit être réduite, c’est la pression sous-glottique qui est diminuée. Si elle n’est pas compensée par le larynx, une diminution de la pression peut cependant affecter la fréquence de vibration des bandes vocales, modifiant alors la hauteur (Sundberg 1987, p. 40).
La nasalisation serait peut-être dans certains cas une stratégie permettant de diminuer l’intensité d’exécution sans affecter la hauteur de note chantée. En effet, à cause de la perte d’énergie acoustique induite par l’abaissement du vélum et la création d’un second canal par où circule le souffle phonatoire, la nasalisation peut facilement causer une baisse d’intensité. Kent (1993, p. 105) souligne d’ailleurs que les sons nasalisés sont en général les sons les moins intenses d’une chaîne phonologique. Ce possible usage « fonctionnel » de la nasalisation, qui pourrait contribuer ici à la stabilité des notes tenues, n’entre cependant pas en contradiction avec son rôle expressif. Le positionnement particulier de nombreuses syllabes nasalisées en fin de phrase et accompagnées d’une baisse d’intensité, coordonné avec le mouvement généralisé d’intensification de la nasalisation identifié plus haut, contribue sans aucun doute à créer l’effet plaintif associé au chant country-western et dont la chanson de Marcel Martel constitue un exemple particulièrement représentatif.
Les icônes du pleur décrits par Fox (2004, p. 276) créent une rupture dans la voix et dans la ligne mélodique et visent à mettre en évidence certains mots, ce qui devrait s’accompagner par une forme d’accentuation. On retrouve de telles voyelles à la fois nasalisées et accentuées dans « La chaîne de nos cœurs ». Elles sont situées en début et en milieu de phrase, et sont présentes dans les mots du titre entendus dans les refrains (« brises » et « chaîne ») ainsi que dans les mots-clés véhiculant le sens de la chanson (« quittes », « chérie », « aimés », « promis », « aimer »). Seules des voyelles correspondant à la fois à des accents toniques (à l’exception du [ɛ] de « aimés » et « aimer ») et à des valeurs longues sont nasalisées. « Abandonnes » est un mot qui résume bien le sens de la chanson. Sa prosodie est cependant imparfaite : c’est la première voyelle, le [a], qui est chantée sur une valeur longue, alors que l’accent tonique est sur le [ɔ]. D’autres mots présentent une prosodie adéquate mais sont peu significatifs (« pourtant », entre autres). Ces mots ne contiennent aucune voyelle significativement nasalisée. Les voyelles nasalisées et accentuées correspondent donc non seulement à des valeurs longues mais elles sont aussi généralement coordonnées avec des accents toniques dont la prosodie est correcte et est située dans des mots significatifs sur le plan du récit.
Par leur caractère accentué, à la fois sur le plan de la durée et de l’intensité, combiné à une nasalisation très marquée, ces voyelles créent bel et bien des ruptures dans la ligne mélodique et vocale, à la manière des cry breaks décrits par Fox (2004, p. 276). Dès le premier refrain, le [i] dans « brises », se démarque des autres voyelles par son intensité, attirant l’attention à la fois sur le titre et sur le récit à venir ; elle marque le sommet dynamique de la phrase.
Exemple 15 : Marcel Martel, « La chaîne de nos cœurs », 1er refrain, « Tu brises la chaîne de nos cœurs »27F0 et courbe d’intensité 00:06.698-00:11.435.. Écouter.
Dans le deuxième couplet, la troisième phrase comporte deux voyelles nasalisées et accentuées, le [i] de « promis » et le [ɛ] de « aimer ». Sans constituer les plus importants sommets dynamiques de la phrase, ils sont cependant accentués dans leur contexte immédiat ; le [i] de « promis » est plus intense que le [o], et le [ɛ] de « aimer » est aussi fort et plus aigu que le [e], qui porte pourtant l’accent tonique du mot.
Exemple 16 : Marcel Martel, « La chaîne de nos cœurs », 2e refrain, « Tu m’avais promis de m’aimer toujours »28F0 et courbe d’intensité 01:53.371-01:58.131.. Écouter.
Ces syllabes ne sont pas nasalisées de manière accidentelle. Comme on l’a vu, la nasalisation atténue en général l’intensité. Nasaliser une voyelle et lui donner une intensité égale ou supérieure aux voyelles environnantes exigent de compenser par le signal vocal ce qui est perdu dans la résonance. De plus, ces voyelles nasalisées sont souvent mises en évidence grâce à d’autres effets vocaux, et des microvariations mélodiques sont notamment utilisées à cette fin. Dans la première phrase de la chanson par exemple, le [i] de « brises » est attaqué environ un ton plus bas que la note cible, qui est ensuite atteinte par glissement mélodique, comme le montre le fondamental visible sur le spectrogramme de l’exemple 17.
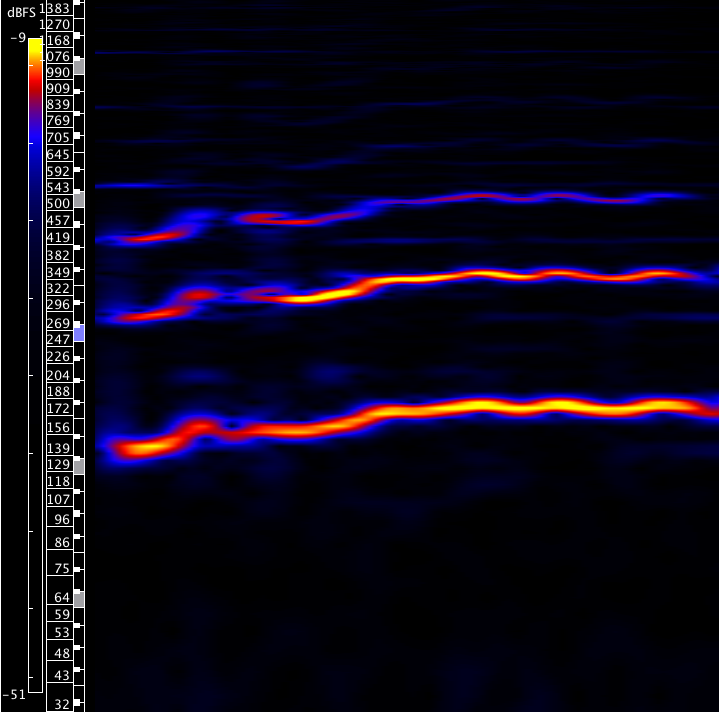
Exemple 17 : Marcel Martel, « La chaîne de nos cœurs », 1er refrain, « Tu brises »29F0 00:06.780-00:08.138..
Ces voyelles sont donc à la fois accentuées et préparées. En plus d’agir comme les cry breaks typiques du style vocal country états-unien et donc comme icônes du pleur, elles ont pour avantage de faciliter l’intelligibilité des paroles en signalant les mots les plus importants du texte chanté ainsi que les accents toniques.
L’usage de toutes ces stratégies vocales semble donc être articulé autour de quelques principes forts dont on retrouve des exemples dans de nombreux autres enregistrements du corpus : adéquation entre accentuation dynamique et accentuation linguistique, mouvement général allant du moins au plus nasalisé, effet de plainte créé par l’emploi de la nasalisation à la fin de la phase d’expiration, lien entre nasalisation et mots significatifs du récit. Tous ces paramètres introduisent dans la performance vocale une véritable structuration. Cela permet de tirer quelques conclusions. Dans la voix country-western, la nasalisation participe bel et bien à la construction d’èthos spécifiques (plainte, tristesse, pleurs) par la mise en commun de variations du timbre, de la hauteur et de l’intensité, dont l’usage semble codifié de manière assez précise. Dans le cas de la plainte, les connotations reliées à la nasalisation semblent être les mêmes pour la voix parlée et pour la voix chantée, ce qui révèle une esthétique en partie fondée sur la parole.
Par ailleurs, la forte structuration dont fait l’objet la nasalisation constitue en quelque sorte une réponse aux critiques adressées à la voix country-western en démontrant une certaine intentionnalité. On parle de « ballades pleurnichardes » (Rioux 1992, p. 73), de « jérémiades » (Taschereau 1977, p. 22), et même les chanteurs se réclamant du country utilisent un tel vocabulaire, par exemple Stephen Faulkner qui confiait à Yves Claudé que « [l]a voix dans le country est souvent lyreuse, plaintive, monotone, nasillarde… c’est son identité » (Claudé 1986, p. 51).
Si ces commentaires tombent dans le mille en associant plainte et nasalité, on a souvent l’impression que ces voix y sont considérées comme de moindre valeur que les autres types de voix populaires, qu’elles sont déficientes et sont typiques de chanteuses et de chanteurs peu formés, voire peu éduqués. Or, on constate que la nasalisation fait l’objet d’un contrôle certain et les analyses présentées dans cet article vont dans le sens des travaux de Maria-Josep Solé (1992) sur la nasalisation dans l’anglais américain. Il faut cependant noter qu’il ne s’agit pas ici d’une intention qui relève constamment de la conscience mais d’une donnée programmée chez le locuteur. L’intentionnalité concerne plutôt l’absence de contrainte phonologique à cette nasalisation, qui découle plutôt d’un usage qu’on pourrait qualifier de culturel. J’avancerais que le phénomène est semblable pour la voix country-western : l’usage de la nasalisation y est intentionnel et, sans nécessairement relever à chaque microvariation d’un geste conscient, s’inscrit dans un complexe stylistique acquis et appris, relevant à la fois de l’expressivité, du narratif, du style individuel et de l’affiliation générique.
Plus que par sa simple présence dans le corpus, la fonction générique de la nasalisation est explicitée par un enregistrement au statut bien particulier. Le 11 janvier 1946, Roland Lebrun enregistre « La vie d’un cowboy », une chanson qui évoque la solitude d’un cow-boy éloigné de son village et de sa bien-aimée. Considéré par l’historiographie musicale québécoise comme le pionnier du country-western parce qu’il a ouvert la voie aux premiers cow-boys chantants (les auteurs-compositeurs-interprètes s’accompagnant à la guitare), Lebrun avait endossé une persona de soldat et mettait de l’avant un répertoire avant tout romantique et patriotique. Avec la fin de la Deuxième Guerre mondiale, les thèmes exploités par le chanteur sont de moins en moins d’actualité et sa popularité décline. Avec « La vie d’un cowboy », il enregistre en 1946, quatre ans après le début de sa carrière, sa première chanson à la thématique explicitement western. Lebrun y emploie une voix première beaucoup plus nasale que dans ses enregistrements précédents ; le même contraste peut être observé à l’écoute de « Mes rêves se réalisent », une chanson romantique dans son style habituel, enregistrée lors de la même séance (Duchesne 2004, p. 3).
L’écart dans les degrés de nasalité de ces deux exécutions est flagrant et se manifeste par des images spectrales distinctives. Sur le spectrogramme de l’exemple 18, qui montre deux phrases tirées de « Mes rêves se réalisent » où les résonances sont particulièrement orales, on note l’absence complète d’antiformants, qui sont au contraire bien visibles dans le spectrogramme d’un extrait de « La vie d’un cowboy » (exemple 19), d’une durée semblable et réalisé avec les mêmes réglages.
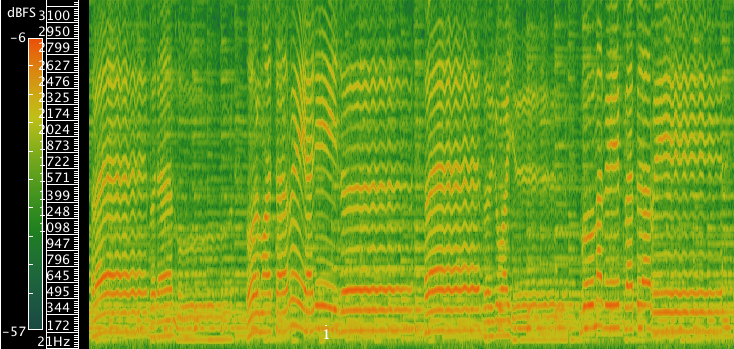
Exemple 18 : Roland Lebrun, « Mes rêves se réalisent »30Spectre harmonique 00:28.305-00:43.287..

Exemple 19 : Roland Lebrun, « La vie d’un cowboy »31Spectre harmonique 00:05.036-00:20.97..
La dimension antiformant est particulièrement évidente lorsqu’on compare les tenus chantés dans ces extraits. La voix de Roland Lebrun dans « La vie d’un cowboy » semble aussi beaucoup plus plaintive, effet auquel contribuent les nombreux glissements mélodiques et les portamentos, qu’on peut voir sur le spectrogramme de l’exemple 19.
Dans le dernier pré-refrain de la chanson, les résonances nasales disparaissent, et la plainte semble s’arrêter alors que le narrateur évoque ses retrouvailles avec sa bien aimée (« Auprès de celle qui m’attend/Je goûterai l’amour ardent »), pour reprendre encore lors du dernier refrain, où une voix nasalisée réapparaît. La transformation du timbre vocal de Roland Lebrun pour ce passage est claire lorsqu’on compare le spectrogramme de la première phrase de la chanson avec la première phrase de ce pré-refrain. Sur les exemples 20 et 21, on voit très distinctement à gauche, les antiformants présents sur le [ə] de « depuis », le premier mot du premier couplet ; à droite, sur le [ə] du mot « de », tiré du troisième pré-refrain, les antiformants sont disparus, et même si ce second [ə] est manifestement moins intense que le premier, tous les harmoniques y sont clairement visibles entre 600 Hz et 1 200 Hz, ce qui n’était pas le cas pour le premier.
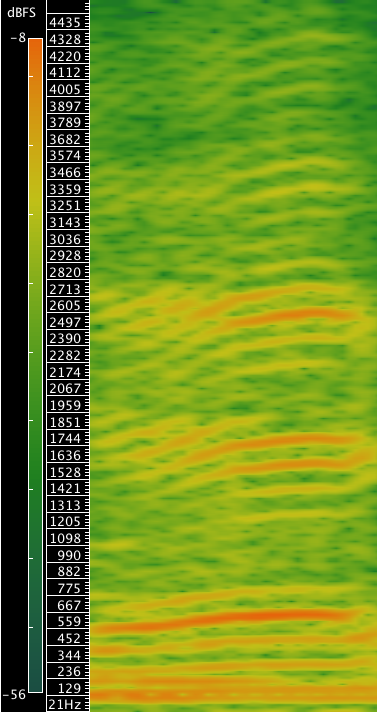
Exemple 20 : Roland Lebrun, « La vie d’un cowboy », 1er couplet, première voyelle de « depuis »32Spectre harmonique 00:05.178-00:05.439..
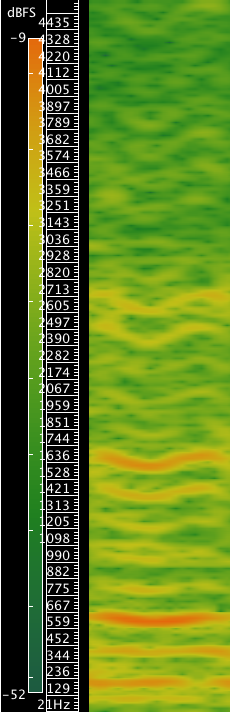
Exemple 21 : Roland Lebrun, « La vie d’un cowboy », 3e pré-refrain, voyelle de « de »33Spectre harmonique 01:51.711-01:51.838..
Comme dans « La chaîne de nos cœurs », la nasalisation occupe ici une fonction expressive, en évoquant la plainte, ainsi qu’une fonction narrative importante, en structurant le récit autour de deux pôles, soit la solitude du temps présent et le bonheur futur. La nasalisation joue cependant ici un rôle générique manifeste et, associée à une thématique western, semble revendiquer l’appartenance du soldat Lebrun à la jeune tradition country-western qui gagne alors de plus en plus d’adeptes.
Conclusion
La nasalisation est bel et bien un trait stylistique important de la voix country-western, et ce, à tous les niveaux d’analyse. Le phonostyle générique, les phonostyles individuels, ceux reliés au contenu narratif des enregistrements et plusieurs types de microvariations reliées à l’expressivité emploient ce modificateur paralinguistique de manière abondante et structurée. À des fins de démonstration, les résultats présentés ici ont peut-être donné l’impression d’un certain cloisonnement des divers niveaux d’analyse. Rien n’empêche de les croiser. Ainsi, on pourrait facilement imaginer comment une certaine combinaison de paramètres et de variations spécifiques, envisagés sur le plan microanalytique, pourraient être à la fois porteurs d’expressivité et typiques, par exemple, d’un phonostyle individuel.
Comme on l’a vu, la nasalisation, avec d’autres paramètres, contribue à la construction d’èthos spécifiques dont le sens semble aisément perceptible, leur mode de représentation étant vraisemblablement fondé sur la parole quotidienne, et partagé par les interprètes et les auditeurs. Les critiques adressées à la voix country-western montrent d’ailleurs une compréhension parfaitement adéquate de la charge expressive attribuée à la nasalisation dans ce répertoire. Bien que l’on puisse rattacher l’émergence du country-western à un mouvement plus ample, soit celui de la diversification que connaît la voix populaire au Québec depuis les années 1920, ses représentants introduisent assurément de nouvelles conventions quant à l’esthétisation des effets paralinguistiques et de l’oralité. Replacer la phonostylistique dans une perspective historique semble ainsi une avenue prometteuse pour la compréhensions des grands courants qui ont traversé la musique populaire québécoise.
Bibliographie
Birch, Peer, et al. (2002), « Velum Behavior in Professional Classic Operatic Singing », Journal of Voice, vol. 16, no 1 (mars), p. 61-71.
Claudé, Yves [sous le pseudonyme d’Yves Alix] (1986), « Le western, une musique qui vient du cœur », Mouvements, vol. 4, no 2 (avril-mai-juin), p. 50-52.
Demolin, Didier, et al. (2003), « Determination of Velum Opening for French Nasal Vowels by Magnetic Resonance Imaging », Journal of Voice, vol. 17, no 4 (décembre), p. 454-467.
Duchesne, Martin (2004), Notes pour Le Soldat Lebrun. Les années Starr, 1942-1953, disque compact, Production XXI-21 XXI-CD – 21501.
Fox, Aaron A. (2004), Real Country. Music and Language in Working-Class Culture, Durham, Duke University Press.
Kent, Raymond D. (1993), « Vocal Tract Acoustics », Journal of Voice, vol. 7,no 2 (juin), p. 97-117.
Lacasse, Serge (2010), « The Phonographic Voice. Paralinguistic Features and Phonographic Staging in Popular Music Singing », dans Amanda Bayley (dir.), Recorded Music. Society, Technology, and Performance, Cambridge, Cambridge University Press, p. 225-251.
Lefrançois, Catherine (2011), « La chanson country-western, 1942-1957. Un faisceau de la modernité culturelle au Québec », Thèse de doctorat, Université Laval.
Le Huche, François, et André Allali (2001), Anatomie et physiologie des organes de la voix et de la parole, tome 1, « La voix », 3e édition, Paris, Masson.
Léon, Pierre (2005), Précis de phonostylistique. Parole et expressivité, Paris, Armand Collin.
Laboratoire de phonétique et de phonologie de l’Université Laval (2004), Identification des sons du français, https://www.phonetique.ulaval.ca/identification-des-sons-du-francais, consulté le 18 avril 2012.
Maingueneau, Dominique (1984), Genèse du discours, Bruxelle, Pierre Mardaga Éditeur.
Maingueneau, Dominique (1993), Le contexte de l’œuvre littéraire. Énonciation, écrivain, société, Paris, Dunod.
Poyatos, Fernando (1993), Paralanguage. A Linguistic and Interdisciplinary Approach to Interactive Speech and Sound, Amsterdam, John Benjamins.
Rioux, Christian (1992), « Quand le country cause français », L’actualité, vol. 17, no 1 (janvier), p. 73-75.
Solé, Maria-Josep (1992). « Phonetic and Phonological Processes. The Case of Nasalization », Language and Speech, vol. 35, no 1-2, p. 29-43.
Sundberg, Johan (1987), The Science of the Singing Voice, Dekalb, Northern Illinois University Press.
Sundberg, Johan, et al. (2007), « Experimental Findings on the Nasal Tract Resonator in Singing », Journal of Voice, vol. 21, no 2 (mars), p. 127-137.
Taschereau, Yves (1977), « Je suis un pauvre cow-boy solitaire… mais riche. À cheval sur nos bons sentiments, les chanteurs western nous envahissent », L’actualité, vol. 2, no 4 (avril), p. 21-25.
Woerther, Frédérique (2007), L’èthos aristotélicien. Genèse d’une notion de rhétorique, Paris, Vrin.
Médiagraphie
Les enregistrements sont présentés par ordre alphabétique d’interprète avec les dates originales de parution. Lorsque la date donnée dans la source consultée correspondait à l’année d’enregistrement plutôt qu’à l’année de parution, la lettre [e] placée ente crochets suit la date. Lorsque l’information est disponible, la face est indiquée. À la fin de chaque référence, une lettre indique de quelle compilation numérique la version utilisée pour les analyses a été tirée.
A Country Québec. Les pionniers et les origines, 1925-1955, Frémeaux et associés FA 5058, 2000.
B Le Soldat Lebrun. Les années Starr, 1942-1953, Production XXI-21 XXI-CD – 2 1501, 2004.
C 20 succès country originaux des années 1940, Unidisc Music (numérique), s.d.
D Hank Snow. The Yodeling Ranger (1936-1947), Bear Family Records BCD 15587 EI, s.d.
Brunelle, Paul
1945, « Mon enfant je te pardonne », 78 tours, RCA Bluebird 55-5231. (A)
[1946 ?], « Sur ce vieux rocher blanc », 78 tours, RCA Bluebird 55-5264-A. (C)
Lamothe, Willie
1948, « L’amour d’une cowgirl », 78 tours, RCA Bluebird 55-5307-A. (A)
1948, « Quand je reverrai ma province », 78 tours, RCA Bluebird 55-5307-B. (A)
1948, « Giddy-Up Sam », 78 tours, RCA Bluebird 55-5300-A. (A)
1949, « Ne me délaissez pas », 78 tours, RCA Bluebird 55-5316-B. (A)
Lebrun, Roland
1946 [e], « La vie d’un cowboy ». 78 tours, Starr 16681-A. (B)
1946 [e], « Mes rêves se réalisent ». 78 tours, Starr 16680-A. (B)
1947 [e], « La mort d’un cowboy des prairies », 78 tours, Starr 16775-B. (B)
Martel, Marcel
1947 [e], « La chaîne de nos cœurs », 78 tours, Starr 16755-B. (A)
Snow, Hank
[1947], « You Broke the Chain that Held Our Hearts », 78 tours, RCA Bluebird 55-3214-B. (D)
| RMO_vol.1.1_Lefrançois |
Attention : le logiciel Aperçu (preview) ne permet pas la lecture des fichiers sonores intégrés dans les fichiers pdf.
Citation
- Référence papier (pdf)
Catherine Lefrançois, « La nasalisation dans la chanson country-western. Un cas de phonostylistique », Revue musicale OICRM, vol. 1, no 1, 2012, p. 90-116.
- Référence électronique
Catherine Lefrançois, « La nasalisation dans la chanson country-western. Un cas de phonostylistique », Revue musicale OICRM, vol. 1, no 1, mis en ligne en novembre 2012, https://revuemusicaleoicrm.org/rmo-vol1-n1/la-nasalisation-dans-la-chanson-country-western/, consulté le…
Auteur
Catherine Lefrançois, Université Laval
Catherine Lefrançois est musicienne et musicologue et elle est titulaire d’un doctorat en musique de l’Université Laval. Sa thèse porte sur les liens entre la chanson country-western et la modernité culturelle au Québec dans les années 1940 et 1950. Elle est actuellement stagiaire postdoctorale à la Faculté de musique de l’Université de Montréal où elle poursuit des recherches sur les phonostyles vocaux dans la musique populaire de la première moitié du XXe siècle et sur leur description dans la presse musicale.
Notes
| ↵1 | Ces recherches doctorales ont été menées grâce au Conseil de recherches en sciences humaines du Canada (CRSH), plus précisément avec le soutien financier du Programme de bourses d’études supérieures du Canada. |
|---|---|
| ↵2 | Aux États-Unis, le mot country avait une connotation rurale forte tandis que western a d’abord été utilisé pour désigner des formes plus urbaines apparues à la fin des années 1930 comme le western swing puis le honky tonk. Au Québec, les termes ont été inversés. Dès l’apparition des premiers enregistrements country, on parle de musique western, terme alors en vogue rattaché à la fois à la production musicale états-unienne et au film western. Le mot western s’entoure cependant progressivement, au Québec, d’une connotation péjorative liée à son rejet, et dans les années 1980 le mot country a alors été utilisé dans une tentative de légitimer cette musique. Afin d’évacuer les connotations respectives attribuées à l’un ou l’autre de ces termes au Québec, et à la suite de plusieurs chercheurs, j’utiliserai le terme country-western pour désigner les manifestations québécoises de la musique country. |
| ↵3 | Toutes les valeurs typiques des formants qui seront données ultérieurement pour les voyelles françaises sont tirées du répertoire Identification des sons du français mis en ligne par le Laboratoire de phonétique et phonologie de l’Université Laval au http://www.phonetique.ulaval.ca. |
| ↵4 | Les exemples désignés par des lettres et précédés du même chiffre sont tirés du même extrait sonore. |
| ↵5 | Formants 01:42.632-01:43.706. |
| ↵6 | Spectre harmonique 01:42.632-01:43.706. |
| ↵7 | Spectre harmonique 00:07.555-00:08.605 |
| ↵8 | Spectre harmonique 00:09.880-00:10.588. |
| ↵9 | Formants 00:09.880-00:10.588. |
| ↵10 | Formants 00:13.490-00:14.001. |
| ↵11 | Spectre harmonique 01:51.502-01:52.965. |
| ↵12, ↵23 | Formants 01:51.502-01:52.965. |
| ↵13 | Formants 02:03.402-02:04.279. |
| ↵14, ↵26 | Formants 00:14.733-00:16.341. |
| ↵15 | Il est évidemment impossible d’affirmer que ce phénomène est causé par la nasalisation. Il n’en accompagne pas moins la nasalisation chez ces deux chanteurs et ce, sur plusieurs voyelles, comme le montreront d’autres exemples à venir. |
| ↵16, ↵17 | Spectrogramme 00:00.000-01:30.006. |
| ↵18 | Les valeurs les plus élevées correspondent aux notes chantées en second mode de phonation. |
| ↵19 | « Crying […] can be iconically represented with specific inflections known categorically as “cry breaks”—sharp deformations of the melodic line effected through intermittent falsetto or nasalization, glottal or diaphragmatic pulsing of the airstream and thus the melodic line, or the addition of articulatory “noise” to an otherwise timbrally “smooth” vocal tone » (Fox 2004, p. 276). |
| ↵20 | « “Crying” effects […] are both generalized aspects of a subgeneric style (“hillbilly” style for example, permits as many cry breaks as possible subject to phonological constraints) and specifically coordinated with “sad” songs, verbs of crying, and affectively potent moments » (Fox 2004, p. 280). |
| ↵21 | Il s’agit du [i] correspondant à l’exemple 5 présenté plus haut. |
| ↵22 | On se rappellera que la dispersion de F2 est l’une des marques de la nasalisation chez Marcel Martel. |
| ↵24 | Formants 01:00.929-01:01.637. |
| ↵25 | Formants 00:09.766-00:11.412. |
| ↵27 | F0 et courbe d’intensité 00:06.698-00:11.435. |
| ↵28 | F0 et courbe d’intensité 01:53.371-01:58.131. |
| ↵29 | F0 00:06.780-00:08.138. |
| ↵30 | Spectre harmonique 00:28.305-00:43.287. |
| ↵31 | Spectre harmonique 00:05.036-00:20.97. |
| ↵32 | Spectre harmonique 00:05.178-00:05.439. |
| ↵33 | Spectre harmonique 01:51.711-01:51.838. |